Machine Learning Experiment Tracking - Introduction
Aug 02, 2025
ML Experiment Tracking: What It Is and Why It Matters
If you have been working as a Data Scientist for a year or two, you surely have seen this:
- You have a long Notebook where you run a bunch of models
- You test these models with different features, hyperparameters, scaling, data preprocessing
- You have got a bunch of metric values with corresponding parameters from the point above
- You are trying to somehow document it
- You start duplicating a Notebook, trying to finalize the model in this Notebook
- You end up with something like
model_final_FINAL_v3_actually_final.ipynb - You get lost and take the model that just feels right.
Sounds familiar?
This is exactly why experiment tracking exists. And why you should care about it.
What is ML Experiment Tracking?
Here's how I formulate experiment tracking:
Logging and tracking all the important stuff about your ML experiments so you don't lose your mind trying to remember what you did.
Every time you train a model, a good experiment tracker captures:
- The exact code you ran (Git commits, scripts, notebooks)
- All your hyperparameters and configurations
- Model metrics
- Model weights/files.
- What data you used and how you processed it
- Your environment setup (Python versions, packages, etc.)
- Charts and visualizations (confusion matrices, learning curves, etc.)
Instead of having this information scattered across your laptop, three different cloud instances, and that one Colab notebook you can't find anymore, everything lives in one organized place.
The real value?
You can access it from anywhere, compare hundreds of experiments with a few clicks, and actually make sense of what you've tried.
Here's how an experiment tracking server comes into play in the ML Lifecycle.
![]()
When your workflow is done right, you can link your tracking system with the model registry to be able to push the best model to production. But more importantly, you can track your choice back in any point in time, which is crucial in real-world ML deployments. Things WILL go wrong, but you just need to be prepared.
How are experiments logged/tracked?
These days, people usually use specialized software, experiment tracking systems.
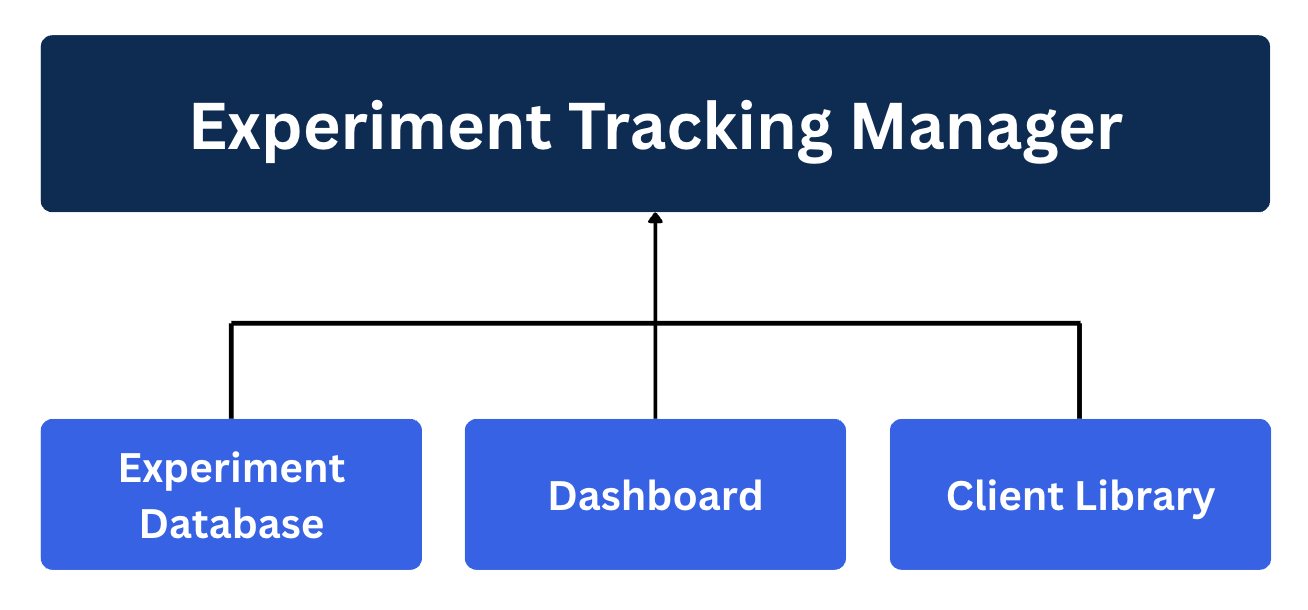
Most experiment tracking systems have three main components:
1. The Database (Your Experiment Memory)
This is where all your experiment metadata gets stored - think of it as your project's long-term memory. It's usually a cloud-based database that can handle structured data (metrics, parameters) and unstructured data (images, model files, plots).
2. The Client Library (Your Logging Tool)
This is the Python library you integrate into your training code. It's what actually sends your experiment data to the database. Most are dead simple to use - just a few lines of code.
3. The Web Dashboard (Your Control Center)
This is the web interface where you visualize, compare, and analyze all your experiments. This part is actually a game-changer for going back and analyzing your experiments.
The Main Use Cases: Why This Actually Matters
After building 10+ industrial ML solutions (while not in all of them using experiment tracking - sad face), I have found the following 4 major use cases for using experiment tracking.
1. All Your ML Experiments in One Place
I just like things to be organized. I believe you do it too.
I have several projects where my team and I did NOT use experiment tracking. The result is that the team had their own experiments locally, and it was just very hard to compare them. Not good.
On the other hand, with experiment tracking, all your experiment results get logged to one central repository.
It does not matter who, where, and how they run them; they are just there. Waiting to be analyzed to help you make money with your ML models.
You don't need to track everything, but the things that you track, you know where to find them.
This makes your experimentation process so much easier to manage. You can search, filter, and compare experiments without remembering which machine you used or hunting through old directories.
2. Compare Experiments and Debug Models with Zero Extra Work
When you are looking for improvement ideas or just trying to understand your current best models, comparing experiments is crucial.
Modern experiment tracking systems make it quite easy to compare the experiments.
What I also like a lot is that you can visualize the way the model/optimizer tends to select hyperparameters. It can give you an idea of what the model is converging to.
From there, you might come up with ideas of how the model can be further improved.
For instance, you can see that your Gradient Boosting tends to select deeper trees, which can mean:
- You might need more data - deeper trees could be a sign that your model is trying to memorize rather than generalize
- Feature engineering opportunity - maybe you can create better features that capture the complexity, allowing shallower (more generalizable) trees
- Regularization adjustment - you might want to tune your regularization parameters to prevent overfitting with those deep trees
Below is an example of tracking an RMSE error based on different hyperparameter values. Cool, isn't it?
![]()
Example of model metrics tracking depending on hyperparameter values. (Source)
3. Better Team Collaboration and Result Sharing
This point is connected to Point 1.
Experiment tracking lets you organize and compare not just your own experiments, but also see what everyone else tried and how it worked out. No more asking "Hey, did anyone try batch size 64?" in Slack.
Sharing results becomes effortless too. Instead of sending screenshots or "having a quick meeting" to explain your experiment, you just send a link to your experiment dashboard. Everyone can see exactly what you did and how it performed.
For me, as for the team leader, this is a big team efficiency booster.
For the team, it's a great energy saver because they can focus on actually improving the models, data quality, code, etc, rather than wasting time finding the model that worked some time ago.
On top, it also becomes easy to collaborate for Data Scientists and ML/MLOps/Deployment Engineers.
![]()
Experiment tracking as the central place between Data Scientists and Model Registry
4. Monitor Live Experiments from Anywhere
When your experiment is running on a remote server or in the cloud, it's not always easy to see what's happening.
This is especially important when you are training Deep Learning models.
Is the learning curve looking good? Did the training job crash? Should you kill this run early because it's clearly not converging?
Experiment tracking solves this. While keeping your servers secure, you can still monitor your experiment's progress in real-time. When you can compare the currently running experiment to previous runs, you can decide whether it makes sense to continue or just kill it and try something else.
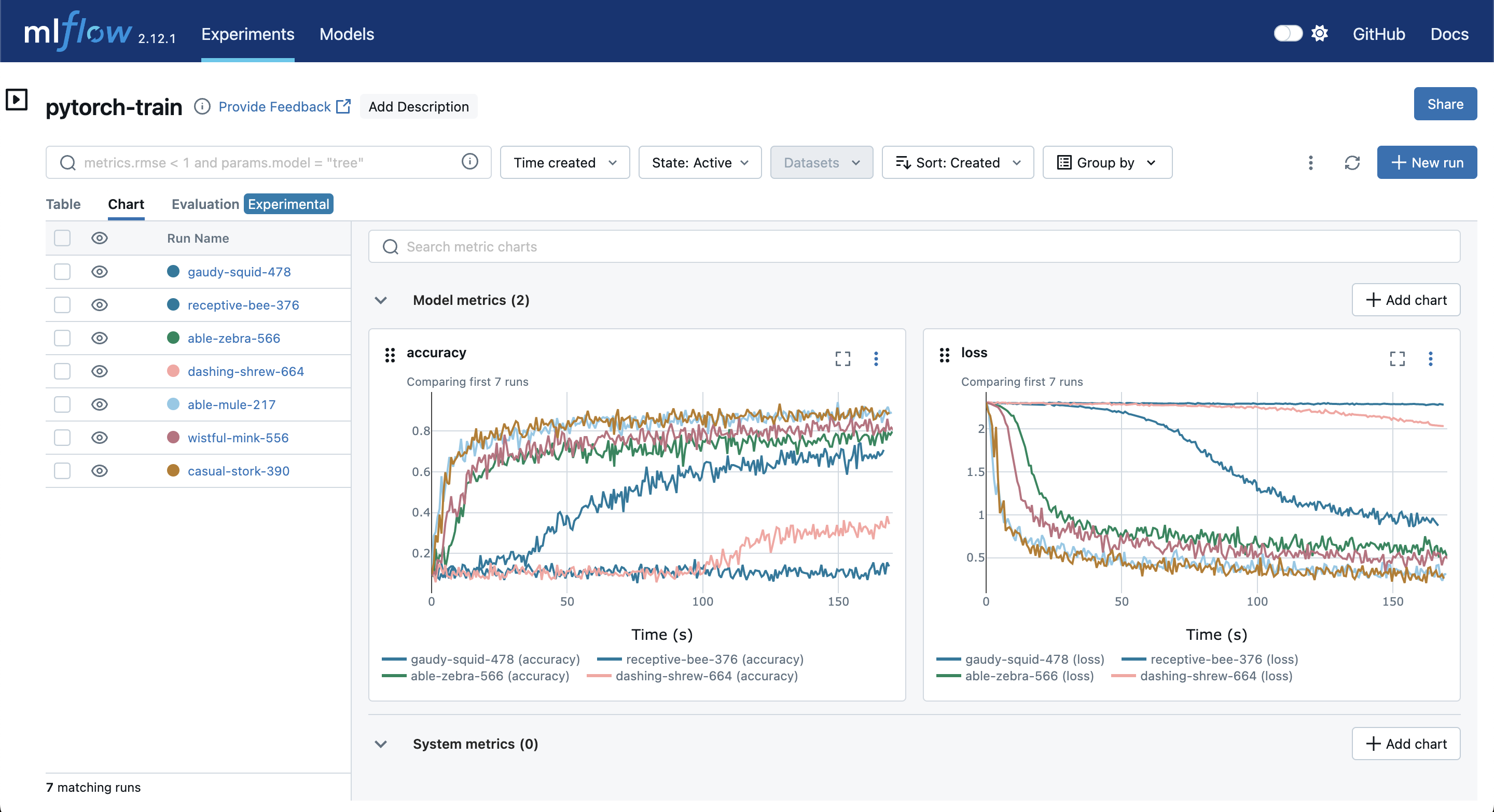
Example of monitoring model loss during training in MLFlow (Source)
What Should You Track? (My Framework)
Here's what I recommend tracking, based on years of painful lessons learned:
The Non-Negotiables
- Code: Git hash, training scripts, notebook snapshots
- Environment: Python version, all package versions, hardware
- Data: Dataset versions, preprocessing steps, train/val/test splits
- Parameters: Every single hyperparameter (trust me on this)
- Metrics: All metrics throughout training, not just final results
- Models: Weights, checkpoints, anything you'd need to reproduce
Highly Recommended (Do This Too)
- Charts: Confusion matrices, ROC curves, learning curves
- Hardware stats: GPU usage, memory consumption (great for debugging)
- Timing: How long training took, convergence speed
- Sample outputs: Best and worst predictions for sanity checks
Domain-Specific Extras
Computer Vision:
- Prediction examples with bounding boxes overlaid
- Data augmentation samples
- Failed cases for error analysis
NLP/LLMs:
- Sample model outputs and the prompts used
- Tokenization details
- Inference speed benchmarks
- Attention visualizations (if you're into that)
Time Series:
- Forecasting examples on validation data
- Feature importance over different time windows
- Seasonality analysis
My rule of thumb: Log more rather than less. Storage is cheap, but recreating lost insights is expensive (and frustrating).
TOP 4 Experiment Tracking Providers (2025 Edition)
My friends, my teams and I've tried pretty much every tool out there. Here are the five I actually recommend:
1. MLflow
Old but gold. MLflow is the open-source king. If you want complete control and don't mind managing your own infrastructure, it's solid. Plus, no vendor lock-in, which some teams really care about.
When to use MLflow:
- You need to keep everything on-premises
- Budget is tight (it's free)
- You want to avoid vendor dependency
- Your team can handle self-hosting
2. Neptune.ai
Neptune is a solid cloud-based experiment tracking platform that handles both individual research and team collaboration well. It has a clean interface and scales reasonably, though it can get pricey as you grow. The collaboration features work as advertised, but you're locked into their ecosystem.
When to use Neptune:
- You want a managed solution that scales from solo research to team production
- Collaboration and result sharing are important for your team
- You're running lots of experiments and need good comparison tools
- You have a budget for a commercial solution and don't mind vendor lock-in
3. Weights & Biases (W&B)
W&B has become huge in the deep learning community. Their visualizations are pretty slick, and the automatic hyperparameter optimization is genuinely useful. Plus, if you're in academia, everyone else is probably using it.
When to use W&B:
- You're doing deep learning (they're optimized for it)
- You want built-in hyperparameter sweeps
- Pretty charts and reports matter to you
- You're in research, where W&B is the standard
4. Comet
Comet is trying to be the full MLOps platform, not just experiment tracking. Especially in the LLM space. Their model monitoring features are decent, and they have some nice enterprise features if that's what you need.
When to use Comet:
- When you have a lot of LLM-related projects
- You want experiment tracking + production monitoring in one tool
- Enterprise features (SSO, compliance) are important
- You like highly customizable dashboards
Conclusions
Here's the bottom line: if you're running more than a handful of ML experiments, you need experiment tracking. Period.
I've seen this too many times (including myself), wasting days trying to reproduce results or compare models manually.
Start simple. Pick one of the tools above (I'd go with MLFlow), and begin logging your basic metrics and parameters. You can always add more sophisticated tracking later.
The key is building the habit. Once experiment tracking becomes part of your workflow, you'll wonder how you ever lived without it.
And trust me, your future self will thank you when you can instantly reproduce that model that worked perfectly six months ago instead of spending three days trying to figure out what you did differently.
The chaos is optional. The organization is a choice.
Make the right one.