Reading time - 7 mins
🥇 Picks of the Week
Best Python dashboard tool, clustering concepts, weekly quiz, and more.
🧠 ML Section
Learn practical tips on how to tune LSTM Neural Networks
Land your next ML job. Fast.
I built the ML Job Landing Kit to help Data Professionals land jobs faster!
✅ Here’s what’s inside:
- 100+ ML Interview Q & A
- 25-page CV Crafting Guide for ML
- 10-page LinkedIn Guide for DS/ML
- 2 Ready-to-use CV Templates
- $40 discount for a TOP Interview Prep Platform
This is the exact system I used to help 100+ clients land interviews and secure ML roles.
🔥 Grab your copy & land your ML job faster!
1. ML Picks of the Week
⏱ All under 60 seconds. Let’s go 👇
🥇 ML Tool
→ How to create Dashboards and User Interface (UI) for your projects in Python? Use Dash, it allows creating complex UI beyond simple dashboards.
📈 ML Concept
DBSCAN vs K Means: when to use what?
🤔 ML Interview Question:
→ How does k-NN algorithm work?
Short answer: KNN is a non-parametric algorithm that classifies or predicts a sample based on the majority (or average) of its k nearest data points (neighbors) in the feature space, using a distance metric like Euclidean or cosine similarity.
Sharpen your k-NN knowledge here.
🗞️ One AI News
Microsoft Launches Free AI Video Generator Powered by Sora
🧠 Weekly Quiz:
→ What is stratified cross-validation?
A) Splitting data randomly into k folds
B) Splitting data so each fold reflects the overall class distribution
C) A method used only for binary classification
D) A technique that prioritizes the majority class samples in each fold
✅ See the correct answer here
2. Technical ML Section
How to tune LSTM models - the guide
Long Short-Term Memory (LSTM) neural networks are a special kind of Recurrent Neural Networks (RNNs) designed to learn long-term dependencies.
What makes LSTMs powerful is their internal memory cell and gating mechanisms, which include the input, forget, and output gates.
These gates allow the network to selectively retain or discard information as it processes sequences step by step.
However, with power comes responsibility - the responsibility of Data Scientists to carefully tune LSTM hyperparameters.
Like all recurrent neural networks, LSTMs have the form of a chain of repeating modules (cells) of a neural network.
The example of this is shown below.
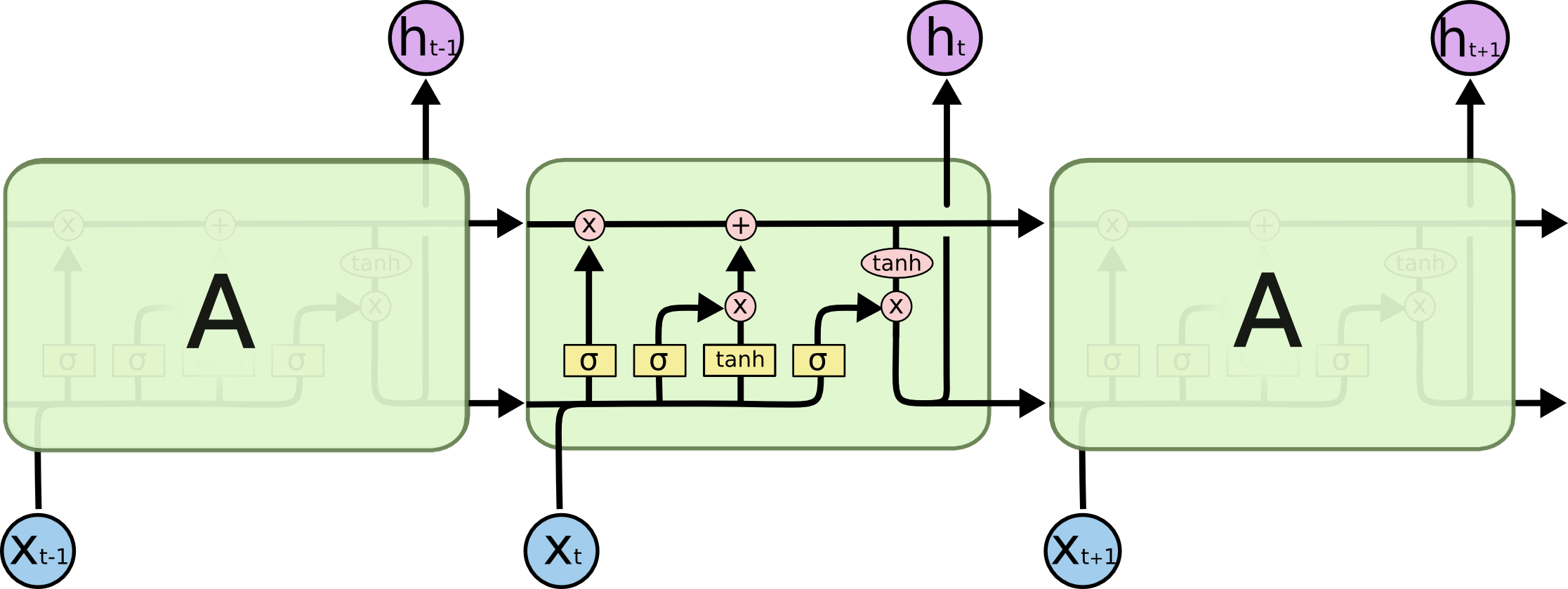
LSTM Neural Network Sequence (Source)
LSTMs are widely used in:
-
Time series forecasting (e.g., energy consumption)
-
Anomaly detection (e.g., industrial sensor data)
-
Natural Language Processing (e.g., text classification, sentiment analysis)
-
Audio/speech processing (e.g., voice recognition)
To fully grasp the idea of how LSTM and RNNs in general work, I suggest you read these articles:
Despite the LSTM power, they are also computationally intensive, sensitive to input design, and prone to overfitting if not tuned well.
This issue will help you understand the key LSTM tuning parameters, with practical tips to avoid overfitting, speed up training, and improve generalization.
LSTM Hyperparameters
These are the main LSTM hyperparameters that are tuned in practice:
1. Learning Rate
Controls how much the model updates its weights at each step of the optimization algorithm.
It is not particularly different compared to other neural networks, and it concerns the optimizer rather than the model itself.
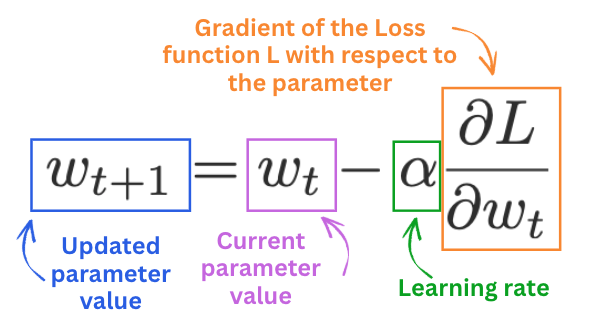
A too-high learning rate causes the model to overshoot minima during optimization, resulting in diverging loss or oscillations.
A too-low learning rate leads to slow convergence or getting stuck in suboptimal points.
Tuning tip:
Start with 0.001.
If the training loss is unstable, reduce it by a factor of 10.
Use log-scale tuning in the range [0.0001 - 0.01].
2. Number of layers
The layer in LSTM is a sequence of LSTM cells. It defines how "deep" the neural network is.

The larger the number of layers, the more complex patterns LSTM can learn.
Tuning tip:
-
1 layer is usually sufficient for simple patterns or short sequences.
-
2–3 layers allow for richer representations but increase the risk of overfitting and vanishing gradients.
-
4+ layers are rarely needed unless working on very large and complex sequence datasets (e.g., long text or audio).
3. Number of LSTM units
Each LSTM unit acts as a memory block that learns a distinct pattern over time, like detecting spikes, trends, or repeating cycles in the input sequence.
Adding more units gives the model greater capacity to capture diverse temporal behaviors.
However, it also increases the risk of overfitting, especially on small or noisy datasets.
-
More units → better representation power
-
Too many → memorization instead of generalization, slower training
Tuning tip:
-
Use 50-100 units for smaller datasets or simpler patterns
-
Use 150-200 for longer sequences or multivariate time series
-
If the model validation loss diverges, try reducing the number of units.
4. Sequence length
Sequence length defines how many past time steps are passed into the LSTM as input for each prediction.
It directly controls how far back in time the model can "look" to make decisions.
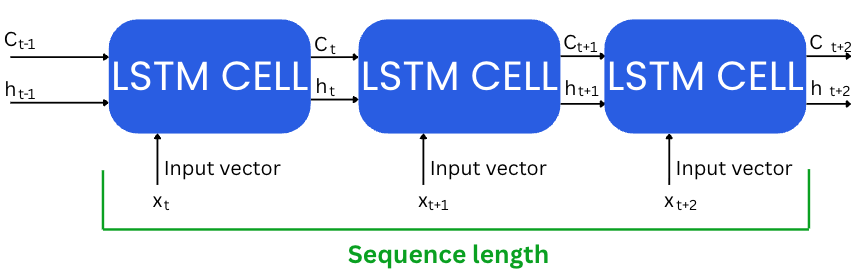
At first glance, longer sequences seem better — more context = better predictions.
But in practice, it's more nuanced.
-
LSTMs don’t remember everything in the sequence equally well. Earlier time steps often get "forgotten" due to the nature of gating and vanishing gradients.
-
Increasing sequence length linearly increases input dimensionality and computational cost (especially with multivariate input).
-
It also increases the chance of feeding irrelevant or noisy history into the model, making training harder.
Tuning tip:
-
A good starting range is between [10-100].
-
Start small, monitor validation loss & memory usage, and increase gradually if needed.
-
Use domain knowledge — e.g., 7-14 for weekly cycles.
5. Dropout rate
Dropout is used to prevent overfitting by randomly setting a fraction of the hidden units to zero during training.
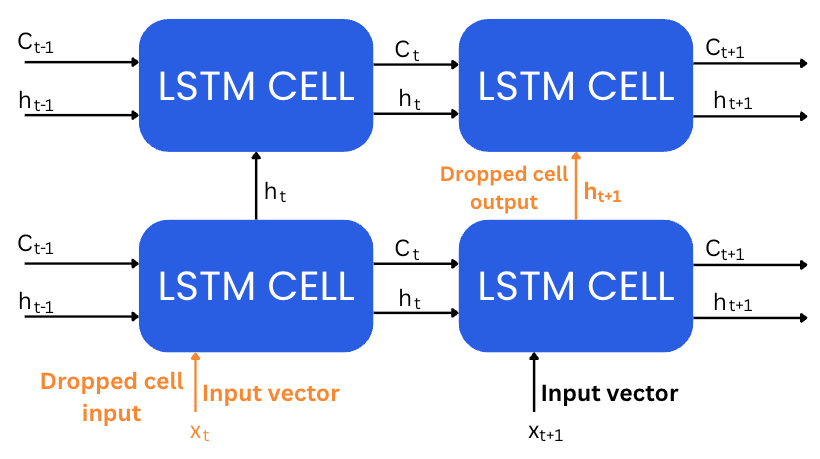
-
Too small (e.g., <0.05) offers negligible regularization.
-
Too large (e.g., >0.5) can suppress learning entirely.
Tuning tip:
Use the range [0.1-0.5] and let the Bayesian optimizer select the best value.
6. Batch size
Batch size defines how many samples are processed before the model performs one weight update.
-
Small batch sizes (e.g., 32-64) create noisy gradients, which improve generalization.
-
Large batch sizes (e.g., 128-512) lead to faster training but can converge to sharper minima with worse generalization.
Tuning Tip:
Start with 32 and monitor training time vs. validation performance.
7. L2 Regularization (Weight Decay)
Weight decay adds a penalty to large weights to reduce overfitting.
It shrinks weights over time, making the model more stable and preventing extreme activations.
-
L2 encourages weight values to stay small without driving them exactly to zero (unlike L1).
-
Useful especially when dealing with noisy features or small datasets.
- Can be combined with Dropout to improve the LSTM generalization.
Tuning tip:
- Start with the value between [0.001-0.01].
- If you want to use dropout, start with Dropout first, then add L2 if needed, especially on noisy or small datasets.
That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Whenever you're ready, there are 3 ways I can help you:
1. ML Job Landing Kit
Get everything I learned about landing ML jobs after reviewing 1000+ ML CVs, conducting 100+ interviews & hiring 25 Data Scientists. The exact system I used to help 70+ clients get more interviews and land their ML jobs.
2. ML Career 1:1 Session
I’ll address your personal request & create a strategic plan with the next steps to grow your ML career.
3. Full CV & LinkedIn Upgrade (all done for you)
I review your experience, clarify all the details, and create:
- Upgraded ready-to-use CV (Doc format)
- Optimized LinkedIn Profile (About, Headline, Banner, and Experience Sections)
Join Maistermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income