Reading time - 7 mins
🥇 Picks of the Week
One line data overview tool, differences in boosting algos, weekly quiz, and more.
🧠 ML Section
Structure your knowledge about Model Registry and why you need to use one.
Land your next ML job. Fast.
I built the ML Job Landing Kit to help Data Professionals land jobs faster!
✅ Here’s what’s inside:
- 100+ ML Interview Q & A
- 25-page CV Crafting Guide for ML
- 10-page LinkedIn Guide for DS/ML
- 2 Ready-to-use CV Templates
- $40 discount for a TOP Interview Prep Platform
This is the exact system I used to help 100+ clients land interviews and secure ML roles.
🔥 Grab your copy & land your ML job faster!
1. ML Picks of the Week
⏱ All under 60 seconds. Let’s go 👇
🥇 ML Tool
→ How to understand your dataset before modeling?
Use ydata (pandas) profiling. It gives you a full EDA report with just one line of code.
📈 ML Concept
XGBoost vs LightGBM vs CatBoost: 5 differences & how to choose the algo
🤔 ML Interview Question:
→ What is the Central Limit Theorem?
Short answer: The Central Limit Theorem states that the sampling distribution of the mean of any independent, random variable approaches a normal distribution as the sample size grows, regardless of the original distribution.
Get a deeper understanding here
🗞️ One AI News
Major 1.0 release of Cursor. Now it reviews your code, remembers its mistakes, and more.
🧠 Weekly Quiz:
→ In time series forecasting, what does a low autocorrelation at lag 1 suggest?
A) Seasonality is strong
B) The series is non-stationary
C) The value at time t is weakly related to time t–1
D) There's a trend in the data
✅ See the correct answer here
2. Technical ML Section
What is Model Registry, and why do you need it in ML systems?
The most fancy job that Data Scientists like to do is to train models.
I agree, it's fun.
You may try a bunch of (some of it unnecessary) stuff, optimize the metrics, do cross-validation, and all this jazz.
But ... training a model is just the beginning.
In real ML systems, the hardest part comes after the model is built.
You need to:
-
Track which model was trained, when, and how
-
Compare it with previous versions
-
Validate performance before deployment
-
Promote only the best to production
-
Roll back instantly when something breaks
If you skip it and hope for the best, I have bad news for you.
At some point, you will end up with:
- Not know which model is currently in production.
- Broken pipelines and no reproducibility.
A Model Registry solves this.
What is Model Registry?
A Model Registry is a centralized system for managing the full lifecycle of ML models.
It lets you:
-
Store models as versioned artifacts
-
Assign models to lifecycle stages (e.g., Staging, Production, Archived)
-
Promote and deploy the best-performing model
-
Roll back if needed
-
Ensure smooth deployment and utilization of trained models.
This is a schematic diagram of the Model Registry concept.
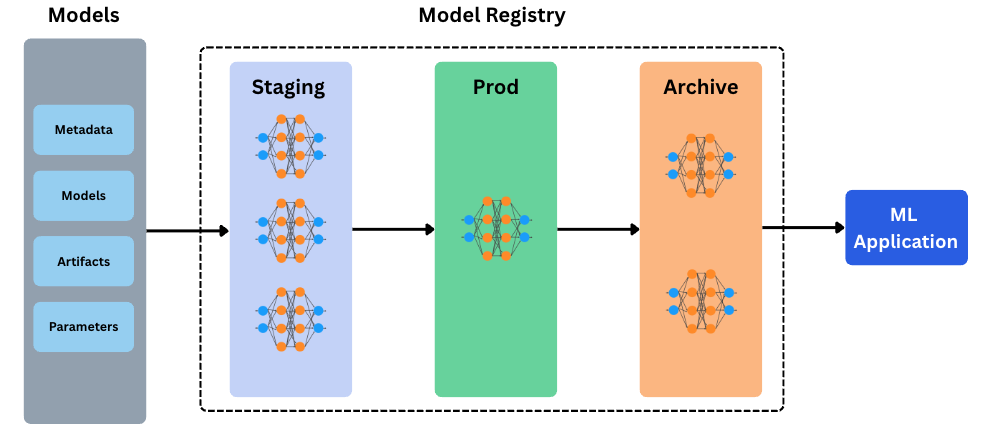
The most commonly used stages in Model Registries are:
-
Staging: Validated models ready for QA or approval
-
Production: Actively used model for inference
-
Archived: Deprecated but preserved for reproducibility/rollback
Where does Model Registry fit in the ML Lifecycle?
Here is a typical cycle of a Machine Learning model:
- The model is trained either locally or in the ML Training Service
- Models, their parameters, and metadata are stored in the artifact storage
- The model is compared with the current production model in the model validation service.
- If the new model is better, it goes from staging to production while the current model is archived.
- The new production model is then deployed to the ML Inference Service through the CI/CD Pipeline.
Let's make a schematic representation of it.
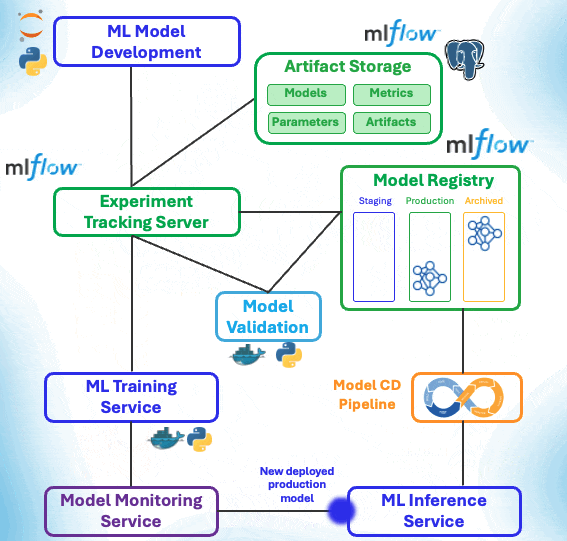
As we see, in some sense, the Model Registry has the central role in the ML Lifecycle, bridging the gap between the training/development phases and inference production phases.
Where does a Model Registry store?
Since the goal of the Model Registry is to fully own model versioning and traceability of the model predictions, it usually stores all required information related to the model.
This is an example of what a Model Registry can store:
-
Model artifact – The actual trained model file (
.pkl,.pt,.onnx, etc.) -
Model version – Unique identifier for the version (e.g., v1, hash, timestamp)
-
Training parameters – Hyperparameters used during training
-
Evaluation metrics – Accuracy, F1 score, AUC, RMSE, etc.
-
Source code version – Git commit hash or link to the codebase
-
Dataset version – Versioned dataset or hash used for training
-
Artifacts – Additional outputs like SHAP plots, confusion matrix, logs
-
Environment info – Python version, dependencies, Docker container details
-
Stage – Lifecycle status:
Staging,Production, orArchived -
Owner/team info – Who trained and registered the model
-
Timestamps – When the model was trained and logged
-
Tags/notes – Custom labels or business-related metadata
What is the difference between Model Registry and Experiment Tracking?
Often, there is confusion between Model Registry and Experiment Tracking.
Let's break them down.
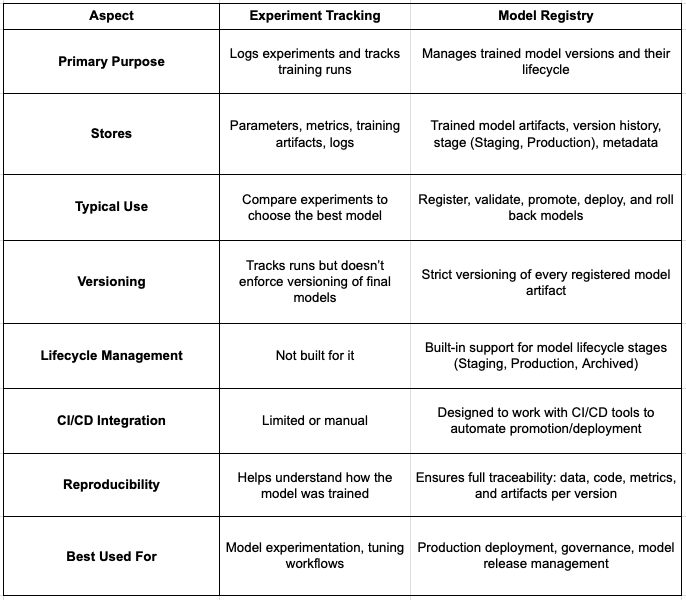
So, in short, a tracking server logs experiments and training runs, while a model registry manages versioned models, their lifecycle stages, and deployment readiness.
What are the main solutions / libraries of Model Registry?
In the current market, these tools are the most widely used for ML Model Registry:
-
MLflow – Open-source; widely adopted for model tracking and lifecycle management
-
Comet – Free for individuals, paid for teams; lightweight registry with experiment tracking
-
Neptune.ai – Free for individuals/small teams, paid for larger orgs; strong UI and model search
Case Study: Weekly Churn Prediction Model
Imagine working at a SaaS company.
You’ve built a churn prediction model that retrains every Monday using fresh customer activity data.
Each week, the model might change slightly — new features, adjusted hyperparameters, different metrics.
If you don’t track all this properly, things can quickly fall apart.
Without a Model Registry:
-
You don’t know which model is in production
-
You can't explain how it was trained
-
You’re manually comparing metrics in a spreadsheet
-
If a bad model is deployed, rollback is messy (or impossible)
With a Model Registry:
Here’s what the process looks like:
-
Training
→ A new model (churn_model_v42) is trained -
Logging
→ It’s registered with full metadata, metrics, and a version ID -
Validation
→ It’s compared to the previous production version -
Promotion
→ If better, it moves to Staging, then to Production -
Deployment
→ CI/CD pipeline deploys the staged model -
Fallback
→ If needed, registry enables instant rollback tov41
What the Registry Stores for Each Weekly Model:
-
Model artifact:
churn_model_v42.pkl -
Model version:
v42with timestamp -
Training parameters: e.g.,
max_depth=5,learning_rate=0.03 -
Evaluation metrics: ROC AUC = 0.87, F1 = 0.78
-
Source code version: Git hash
c1a9f7b -
Dataset version: e.g., customer_data_2024_Week_36.csv
-
Artifacts: SHAP plots, feature importance graphs, confusion matrix
-
Environment: Python 3.10, scikit-learn 1.3.2
-
Stage:
StagingorProduction -
Owner: DS team member who ran the pipeline
-
Tags:
weekly_run,churn,v42 -
Notes: “Slight feature drift observed, but performance improved.”
That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Whenever you're ready, there are 3 ways I can help you:
1. ML Job Landing Kit
Get everything I learned about landing ML jobs after reviewing 1000+ ML CVs, conducting 100+ interviews & hiring 25 Data Scientists. The exact system I used to help 70+ clients get more interviews and land their ML jobs.
2. ML Career 1:1 Session
I’ll address your personal request & create a strategic plan with the next steps to grow your ML career.
3. Full CV & LinkedIn Upgrade (all done for you)
I review your experience, clarify all the details, and create:
- Upgraded ready-to-use CV (Doc format)
- Optimized LinkedIn Profile (About, Headline, Banner, and Experience Sections)
Join Maistermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income