Reading time - 4 mins
1. Technical ML Section
Summary of Gradient Boosting hyperparameters and tips to tune them that work in practice.
The full article is here (reading time - 6 mins).
2. Career ML Section
3 myths about Machine Learning Resume that decrease your job search chances.
1. Technical ML Section:
(For a more detailed discussion, read the full blog article!)
Gradient Boosting is one of the most powerful machine learning algorithms that builds an ensemble of simple models (typically shallow decision trees).
Each new model corrects the errors made by the previous one.
Despite powerful, it has many hyperparameters that need to be tuned carefully.
In this article, we dive into the main Gradient Boosting hyperparamers and the practical strategy to tune them.
👉 Key Gradient Boosting Hyperparameters
Among all the Gradient Boosting Hyperparameters, these five are the most important ones:
📌 Learning rate (aka shrinkage, eta)
Learning rate (shrinkage) parameter multiplies the output of each weak learner (tree).
Decreasing this parameter makes the boosting process more conservative because smaller boosting steps are taken.
📌 Tree Depth
Defines how complex each tree can be. Deeper trees capture more complex patterns but may overfit.
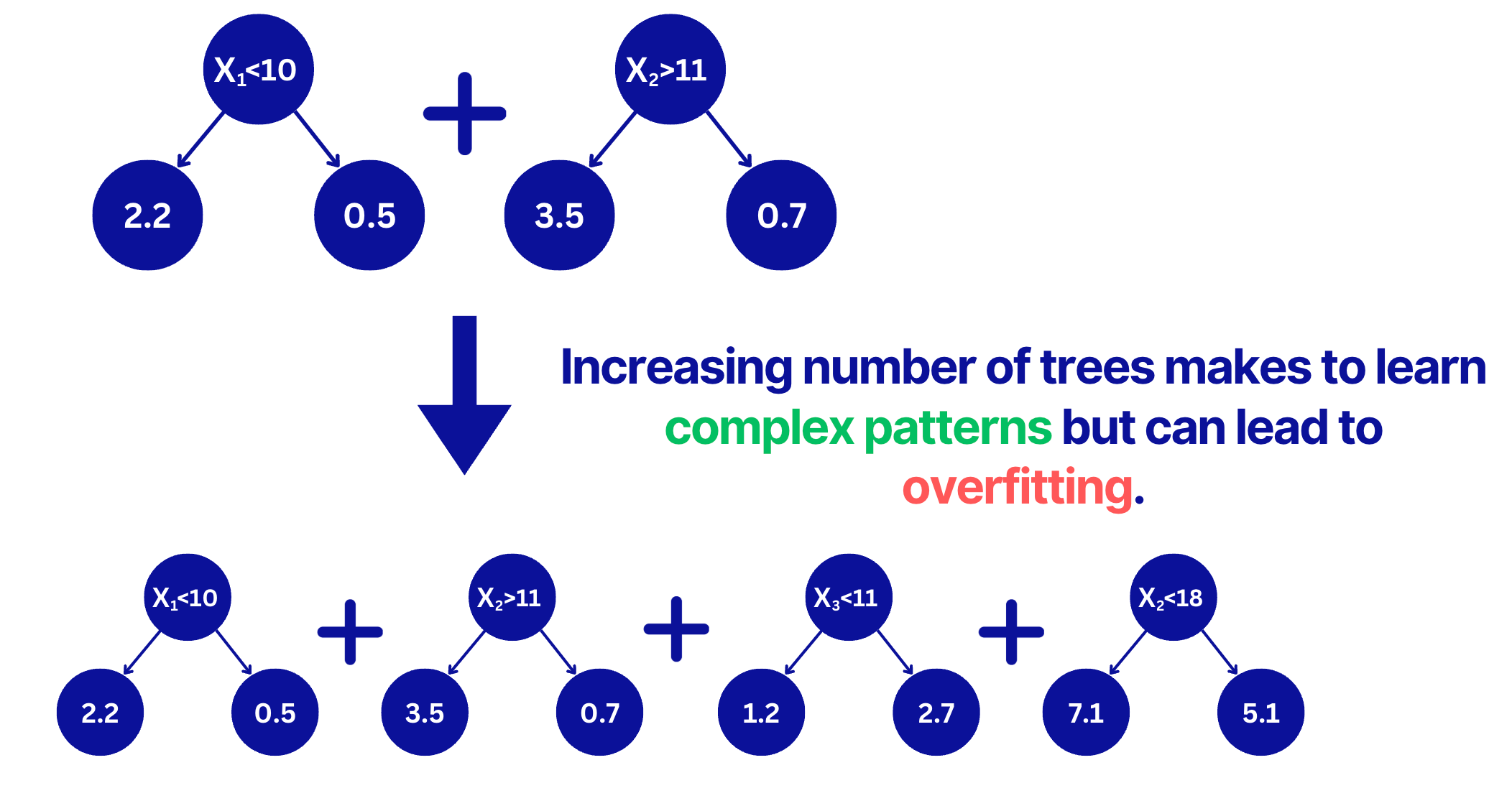
📌 Number of Trees (with Early Stopping)
The number of trees will make the algorithm learn more complex patterns (reduce the bias but increase the variance). A big number of trees will drive the algorithm to overfit.
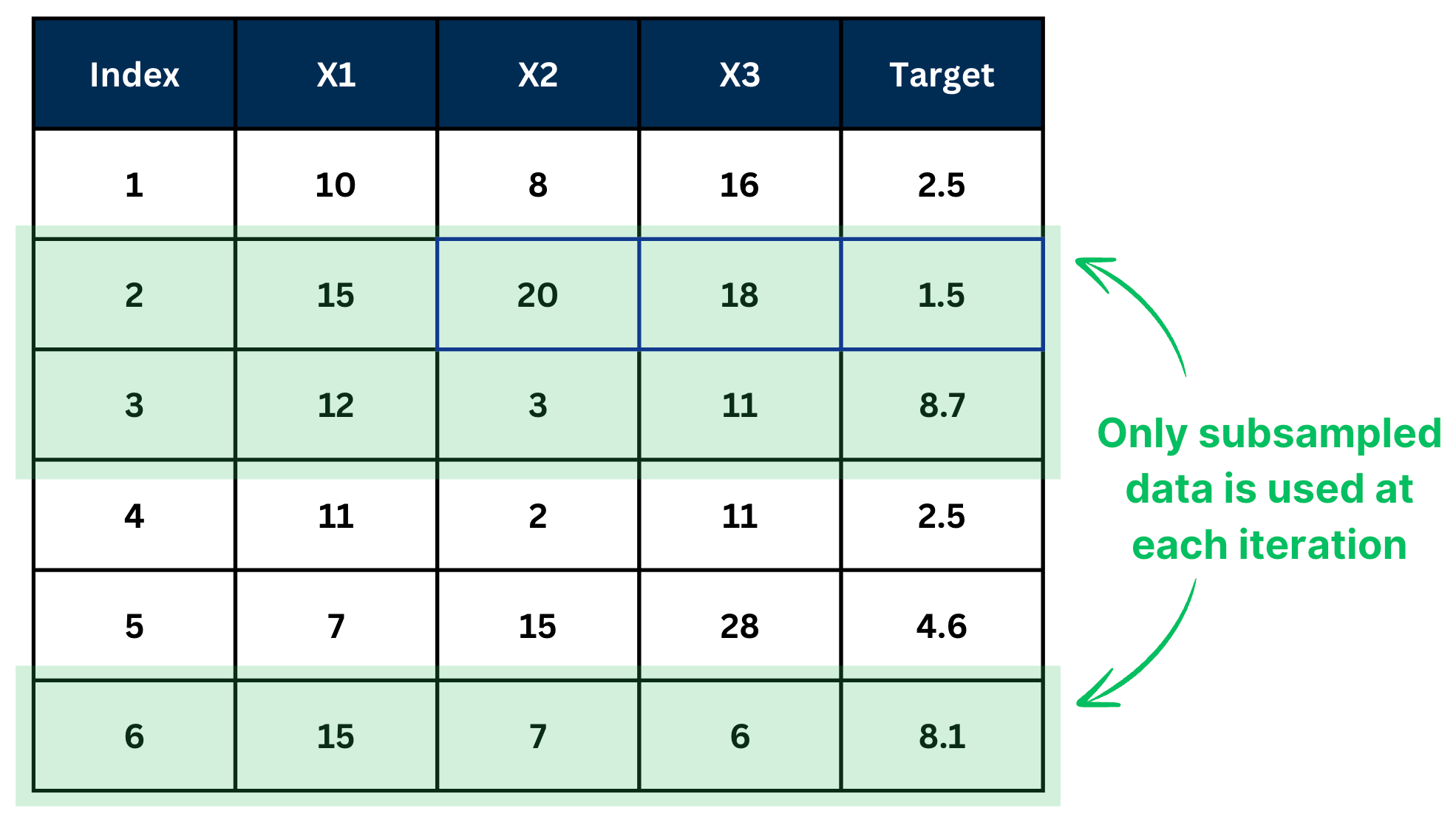
📌 Subsample ratio
Subsample ratio defines how much data is used to fit a decision tree at each iteration step.
If subsample ratio=0.5, it means 50% of the data is used to fit a decision tree. Subsampling is performed at each iteration.
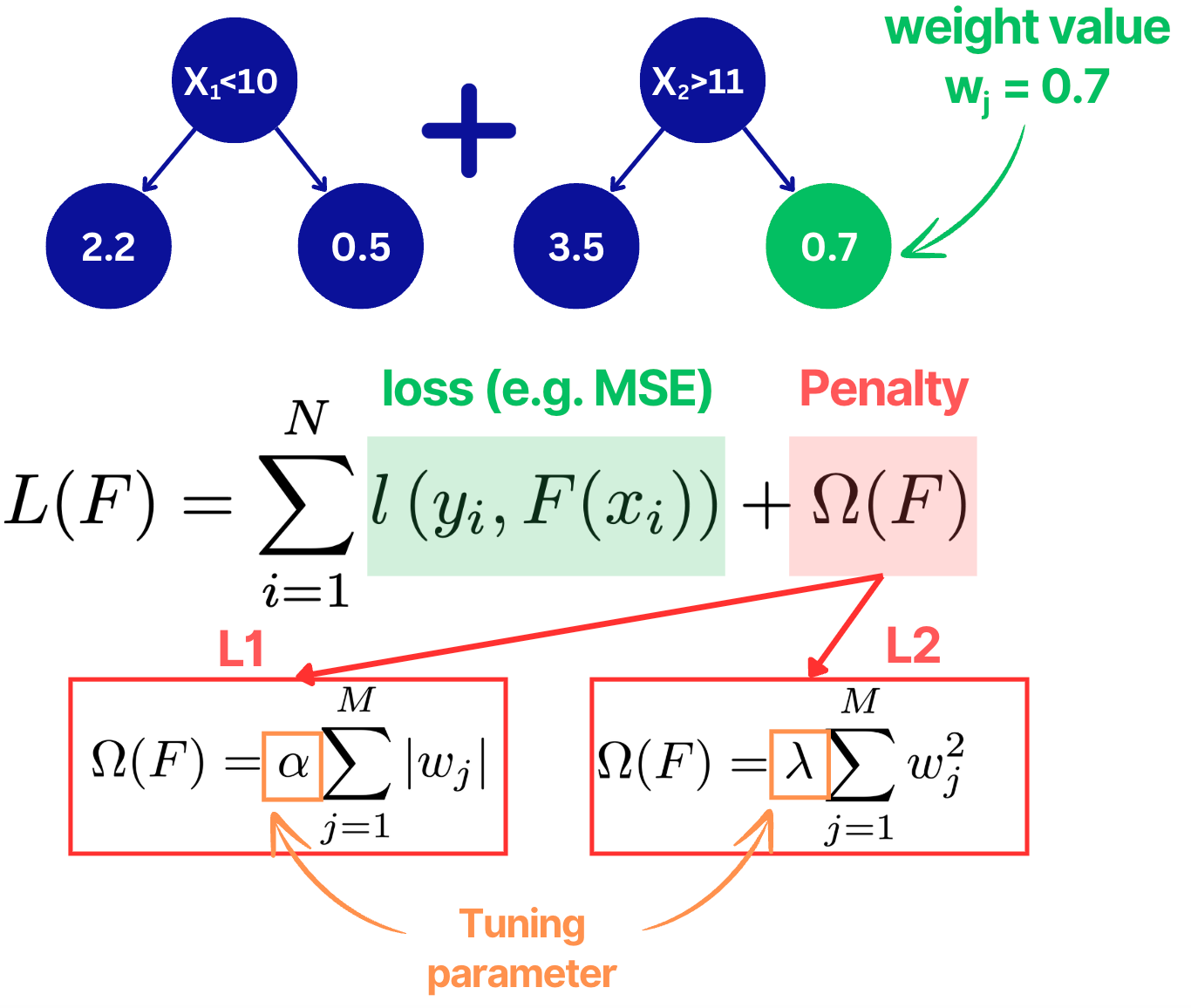
📌 L1/L2 regularization
In Gradient Boosting, L1/L2 regularization penalizes weight values that are located at the leaf nodes.
Similar to linear regression, in L1, sum of the absolute leaf weight values are taken while for L2 - sum of squared values.
Gradient Boosting Hyperparameter Tuning Tips
✅ Tip 1. Use these steps to tune learning rate, tree depth & number of trees:
-
Fix a high number of trees (e.g., 500-1000).
-
Tune learning rate and tree depth first.
-
Use early stopping (15-20 rounds of no improvement) to find the optimal number of trees.
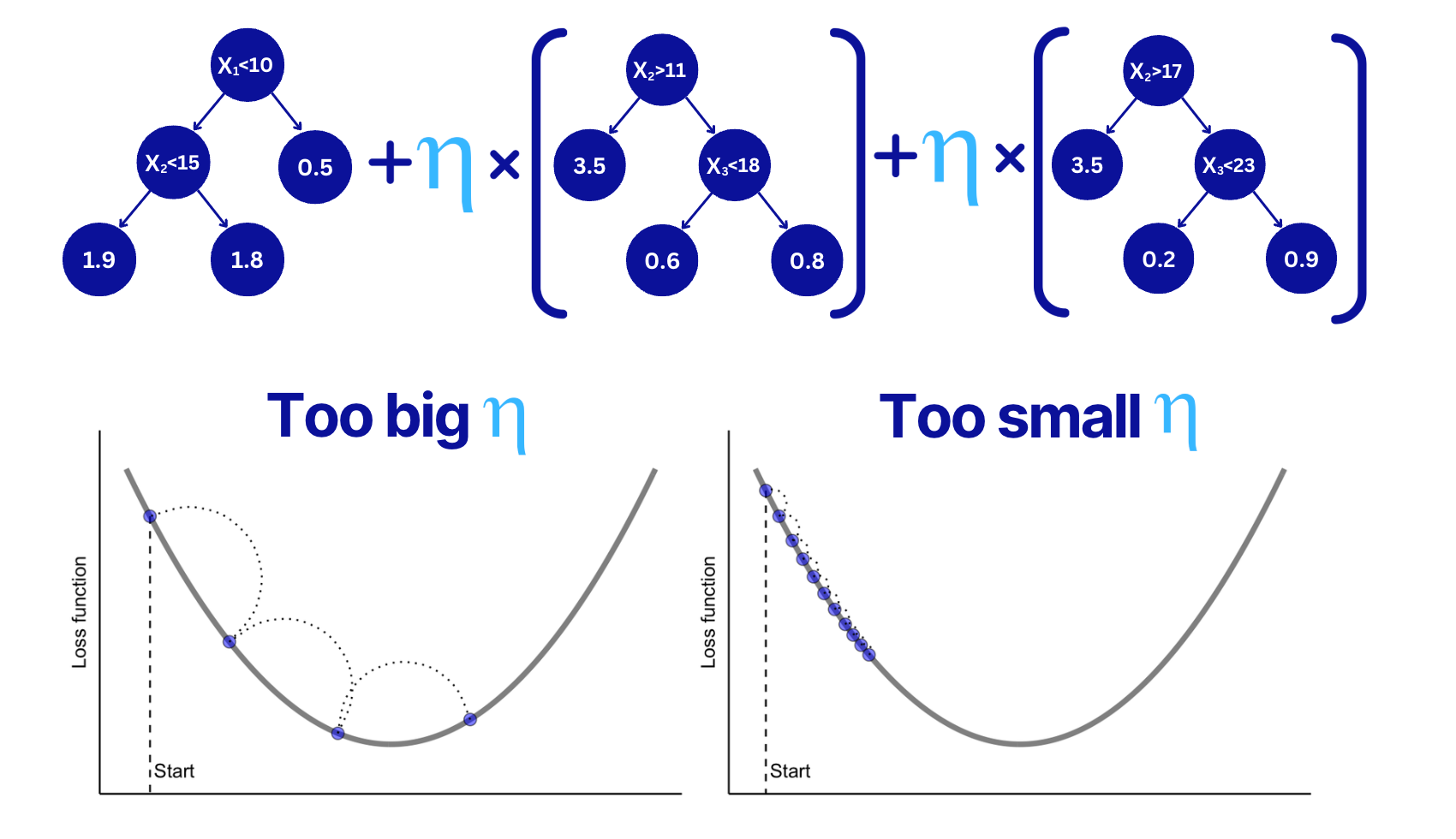
✅ Tip 2. Use log scale for the learning rate range.
Lower Bound: 0.001
Upper bound: 0.05
Good default value: 0.01
✅ Tip 3. Tune based on the data size
Small datasets: Stick to shallower trees (depth 1-3) to prevent overfitting.
Large datasets: Can handle deeper trees (depth 1-6) to capture complex patterns.
✅ Tip 4. Choose either L1 or L2 Regularization, not both
L2 (reg_lambda): Default choice, useful when features are correlated.
L1 (reg_alpha): Helps with feature selection by shrinking irrelevant ones.
✅ Tip 5. Avoid Low Subsample Ratios
Using too little data per tree can lead to unstable models, while using too much increases overfitting risk.
Good range: [0.3, 0.7], default value = 0.5.
✅ Tip 6 Use Bayesian Optimization
Tuning 4-5 hyperparameters can be computationally expensive. Bayesian Optimization (via Hyperopt or Optuna) helps find good values faster.
Good default value for n_iterations = 100.
✅ Tip 7: ALWAYS use k-fold cross-validation.
Avoid using only 1 validation fold.
For time series, also never make shuffle=True, use only nested (sliding) cross validation.
2. Career ML Section
3 myths about Machine Learning Resume that decrease your job search chances.
🟠 Myth 1: Resume HAS TO be 1 page
IT DOES NOT.
This is the most terrible advice that you can follow.
The goal of your Resume is to give a snapshot of what value you can bring
If you squeeze your resume into one page without showcasing your achievements, you’ll end up looking just like everyone else.
On top of that, it will force you to use small fonts which will make it hard to read.
Takeaway: If showing your achievements make more than 1 page, IT IS FINE.

🟠 Myth 2: You need to list everything you did in your Resume.
This is another extreme. I have seen Resumes of 10 pages (I swear) that described every single activity the people did. Don’t do this either.
Good rule of thumb: 1 page per 3-5 years of experience
🟠 Myth 3: More Buzzwords = Better Resume
Wrong. Buzzwords like “result-oriented” “team player” or “innovative thinker” doesn’t impress anyone.
Instead, show YOUR IMPACT.
For example, instead of saying “Data-driven leader” say “Implemented X strategy, improving Y metric by Z%.”
That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Join MAIstermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income