Reading time - 7 mins
1. ML Picks of the Week
A weekly dose of ML tools, concepts & interview prep. All in under 1 minute.
2. Technical ML Section
Learn why Random Forest should be your go-to as a baseline model
3. Career ML Section
Let's discuss if ML Course Certificates help you get a job
1. ML Picks of the Week
🥇ML Tool
Python Library Optuna
Optuna automates hyperparameter tuning to boost your model's performance — fast and efficiently.
Optuna uses Bayesian Optimization under the hood and is especially powerful for:
-
Hyperparameter tuning of complex models
-
Reducing manual trial-and-error in tuning experiments
If you are not using Optuna yet for hyperparameter optimization, start now!
📈 ML Concept
LASSO Regularization
Lasso Regularization (L1) is a technique used to prevent overfitting by adding a penalty to the loss function.
-
encourages sparsity by shrinking some weights exactly to zero
-
helps with feature selection in high-dimensional datasets
It works by adding the absolute value of weights to the loss, forcing the model to focus on the most important features.
Widely used in linear models, but can be used on other ML models like Neural Networks or Gradient Boosting.
Learn more about Lasso Regularization HERE
🤔 ML Interview Question
What is the purpose of cross-validation?
Cross-validation helps you estimate how well your model generalizes to unseen data.
It balances the risk of:
-
overfitting (great performance on train, poor on test)
-
underfitting (poor performance on both train and test)
By splitting the data into train/test folds multiple times, it gives a more reliable performance estimate than a single train/test split.
Learn more: Great Cross-Validation Guide
2. Technical ML Section
Why Random Forest should be your go-to as a baseline model
1️⃣ What is Random Forest?
Random Forest is a Machine Learning model that is based on the bagging concept.
Bagging stands for Bootstrap Aggregating — it's an ensemble technique used to reduce variance and improve model stability and accuracy. This is a great article to dive into bagging.
In short, it works as follows:
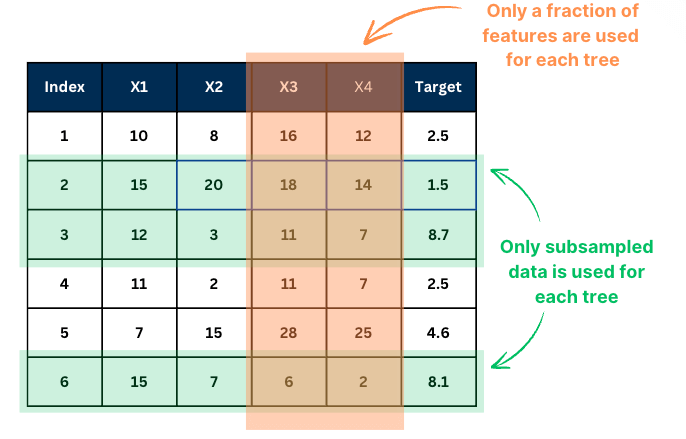
Step 1. Bootstrap Sampling:
Create multiple datasets by sampling with replacement from the original training data.
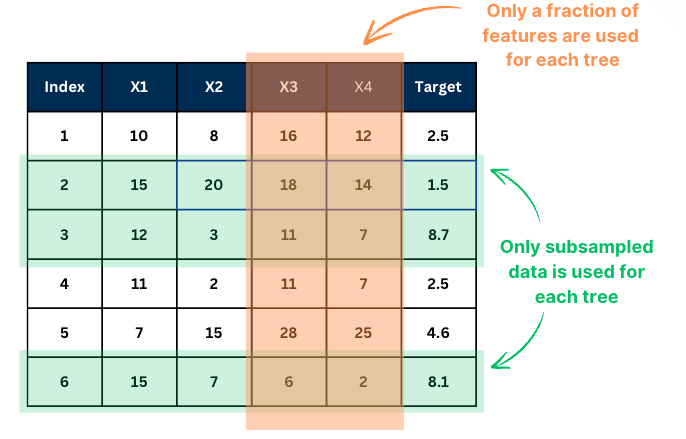
Step 2. Train Models:
Train a separate model (decision tree) on each of these bootstrapped datasets.
Step 3. Aggregate Predictions:
-
Classification → use majority voting
-
Regression → use averaging
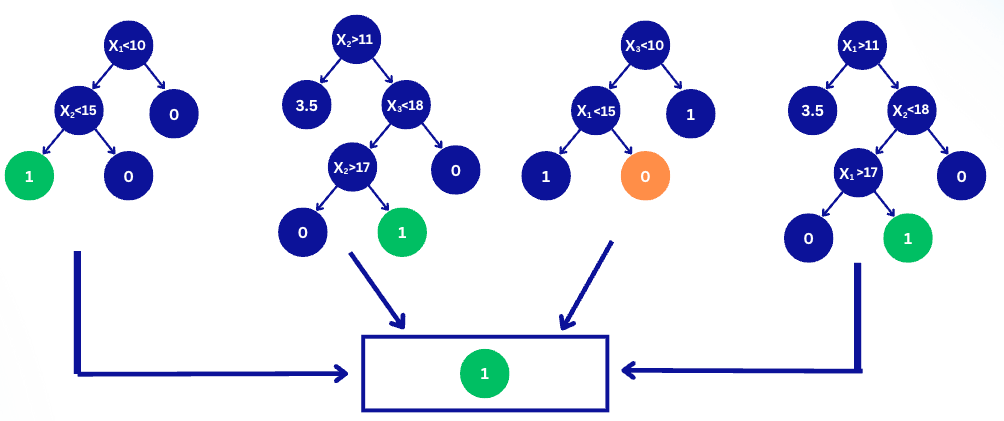
2️⃣ TOP 3 Random Forest Advantages
✅ Advantage 1: Hard to overfit out-of-the-box
Random Forest is designed as a “self-regularizing” algorithm. There are 2 reasons for that.
Reason 1:
For each tree, a data subset is used which reduces the chance for each tree to overfit the dataset.
This means that by default, the algorithm cannot overfit to the data.
It simply "does not" all of it (smart, huh?)
Reason 2:
As the number of trees grows, the model variance decreases while the model bias does NOT increase.
In the figure below, we see that the total model variance is:
- proportional to the correlations between the trees.
- inversely proportional to the number of trees.
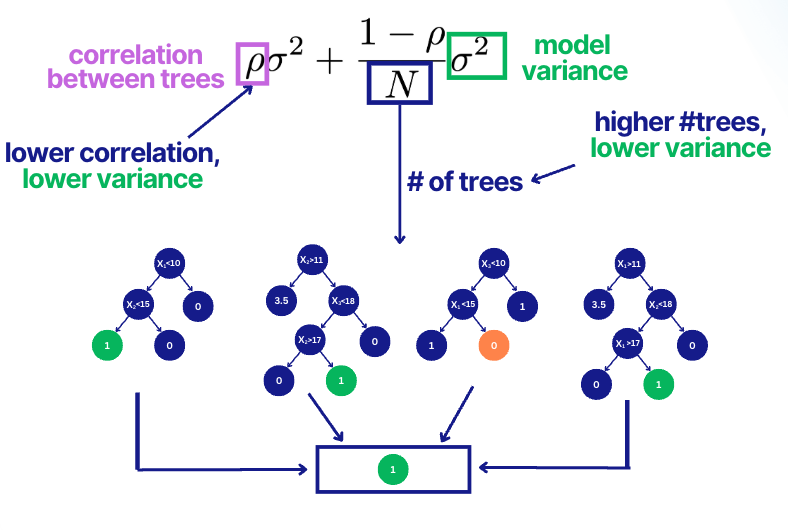
This Random Forest feature makes it great to be your baseline model because you don't need to spend much time on hyperparameter tuning.
A good default value for the number of trees can be between 100 & 500, depending on your dataset.
✅ Advantage 2: Built-in Feature Importance
In Random Forest, decision trees use a certain criterion to make a slit in each node, see the figure below.
In classification, Gini or Entropy Criteria are often used.
In regression, Squared or Absolute Errors are often used.
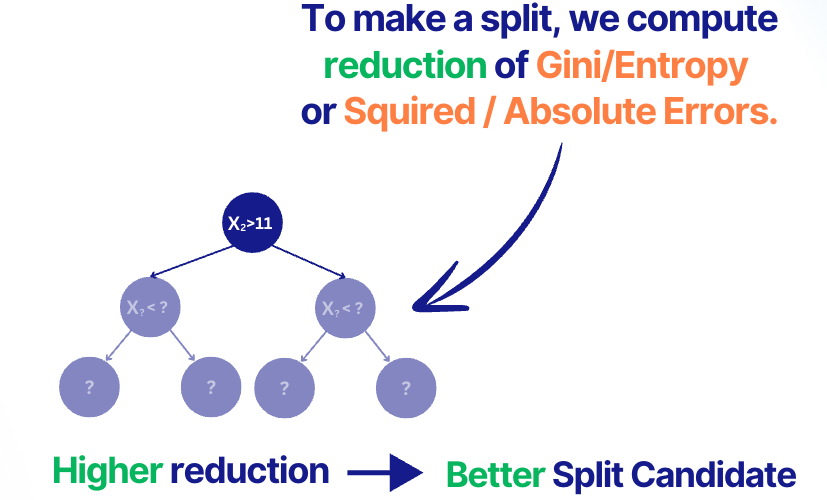
How to use it for feature importance?
We can rank features based on how much they reduce the criterion. The more, the better (see the figure below).
This is easily done because the reduction for each feature is calculated during the model fitting.
This feature importance method is not ideal, but since it comes for free, you can use it out of the box.
This allows you to quickly identify if your ML model's feature importance makes sense in general. And which features are good predictors for the target.
✅ Advantage 3: No feature scaling is required
Decision trees DO NOT require feature scaling.
That makes an ML solution less error-prone, especially in real-time production pipelines.
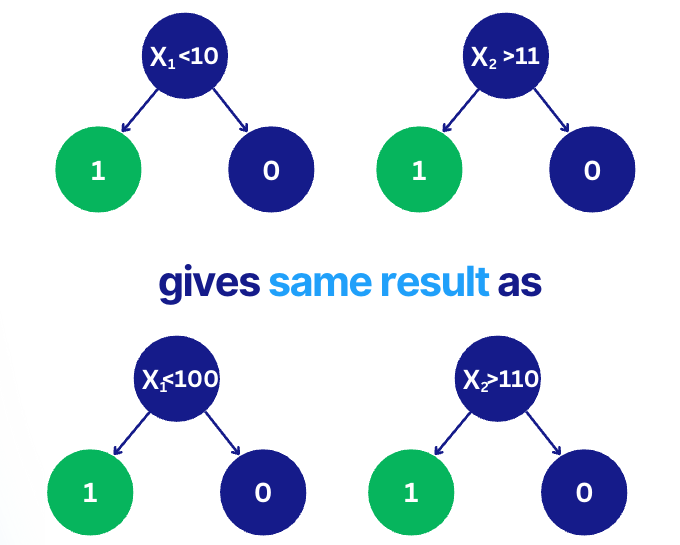
3️⃣ Summary
Random forest is a great baseline model because:
- It is not prone to overfitting -> little to no hyperparameter tuning is required
- It has a built-in feature importance -> quick identification if your features make sense. Straight after your first model is trained.
- No feature scaling is required -> hard to make mistakes, allows quick experimentation, and is easier to implement in production pipelines.
2. ML Career Section
Do course certificates help to get a job?
The short answer is NO.
There are several reasons for that:
✅ Reason 1: Too many certificates are in the market now
Recruiters and Hiring Managers simply don't know which course certificates out of (tens of thousands?) are worth.
They don't know the curriculum, they don't know the depth of the program, and they don't know the teachers of those programs.
Sure, they might know the institution, but here is the second reason.
✅ Reason 2: Nobody cares about the course issuer/institution name
Look, why do people get hired?
They get hired because the employer & hiring team think that the person will be able to make more money for them than they spend on giving the salary.
That is it.
University names used to be a good proxy of the people's ability to solve problems, but they are not anymore.
Companies care about your ability to solve problems and make money for them. These days, the certification names barely correlate with these abilities.
✅ Reason 3: Everyone has tens of certificates
Being a Hiring Manager for 4 companies and screening 750+ CVs, I can tell you with 100% certainty - everyone has the online certificates.
Conclusion? They don't make you stand out. Period.
🤔 OK, Timur, but what to do?
My general advice - focus on building end-to-end ML Projects because:
- They show your ability to solve problems independently
- They show your ability to complete projects end-to-end
- The above two show your ability to potentially make money for companies.
That is it for this week!
If you haven’t yet, follow me on LinkedIn where I share Technical and Career ML content every day!
Whenever you're ready, there are 3 ways I can help you:
1. ML Career 1:1 Session
I’ll address your personal request & create a strategic plan with the next steps to grow your ML career.
2. Full CV & LinkedIn Upgrade (all done for you)
I review your experience, clarify all the details, and create:
- Upgraded ready-to-use CV (Doc format)
- Optimized LinkedIn Profile (About, Headline, Banner and Experience Sections)
3. CV Review Session
I review and show major drawbacks of your CV & provide concrete examples on how to fix them. I also give you a ready CV template to make you stand out.
Related Articles:
Join Maistermind for 1 weekly piece with 2 ML guides:
1. Technical ML tutorial or skill learning guide
2. Tips list to grow ML career, LinkedIn, income